Monitoring - Logstash
Présentation
Logstash
Logstash est un outil de collecte, analyse et stockage de logs. Il est développé en Java, sous licence Apache 2.0. Il parse des fichiers en entrés et les envois à elasticsearch au format JSON.
Métadonnée
Les métadonnées contiennent le détail (Accès, Utilisateur, Groupes, Taille, Date d'accès, ...) de tous les fichiers et répertoires présents sur un serveur. L'extraction des ces dernières ce fait avec les commandes suivantes:
find / -exec ls -ld {} + > server-mtime.lst
find / -exec ls -ldu {} + > server-atime.lst
find / -exec ls -ldc {} + > server-ctime.lst
L'on récupère donc 3 fichiers:
*-mtime.lst: qui comprend la liste des fichiers/répertoires avec la dernière date de modification (modify time)*-atime.lst: qui comprend la liste des fichiers/répertoires avec la dernière date d'accès (acces time)*-ctime.lst: qui comprend la liste des fichiers/répertoires avec la dernière date de changement de permission/droit (change time)
Output
Les fichiers en sortie sont ensuite parsés par Logstash et envoyés à Elasticsearch pour une analyse sur l'état des fichiers (Type de fichier/Dernière accès/Doublons...) avec Kibana.
Voici le résultat en sortie:
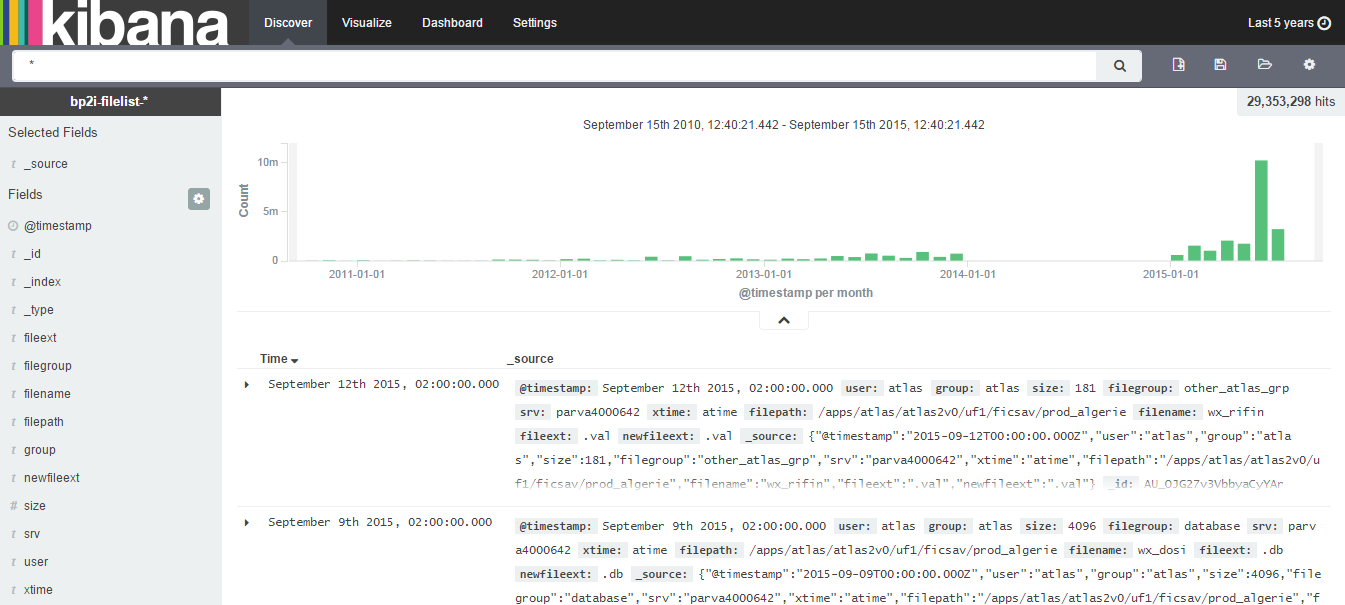
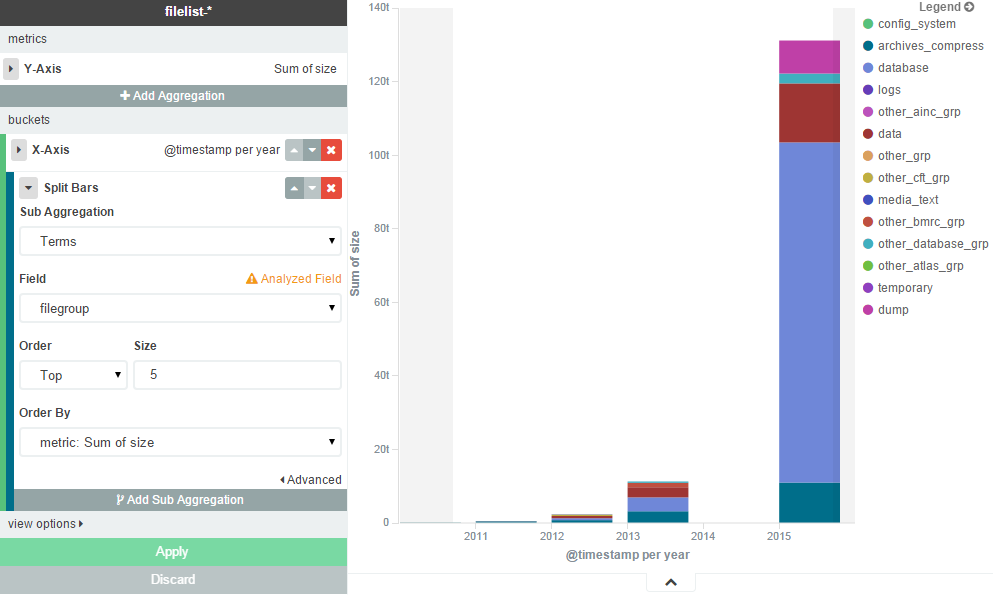
Config Logstash
Générale
Logstash fonctionne avec un fichier de configuration se trouvant dans le répertoire /etc/logstash/conf.d/. Voici un exemple de fichier de configuration typique de Logstash que l'on nommera logstash.conf:
input {
stdin { }
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestanp", "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch { host => localhost }
stdout { codec => rubydebug }
}
On constate donc que le fichier de configuration se compose en 3 parties:
- La partie Input prend en valeur des plugins qui correspondent à ce que peut prendre en entrée l'agent (comme, par exemple, l'entrée standard ou le contenu d'un fichier).
- La partie Filter prend en valeur des plugins qui permettent de manipuler l'événement en le parsant, filtrant ou en ajoutant des informations issues du parsing ou non.
- La partie Output prend en valeur des plugins qui permettent de préciser où seront envoyés les événements (comme, par exemple, la sortie standard ou ElasticSearch).
Pour exécuter le fichier de configuration, il suffit ensuite de rentrer la commande suivante:
Input
Plugin File
Le plugin file permet de sélectionner un ou plusieurs fichiers en entrée.
input {
file {
path => "/mnt/analyse_vol/lst/atime/*.lst"
start_position => "beginning"
sincedb_path => "/dev/null"
codec => plain {
charset => "ISO-8859-1"
}
}
}
- Le paramètre path permet de sélectionner le chemin, par exemple pour sélectionner un fichier spécifique en entrée (
path => /home/log/file1.lst) ou pour sélectionner tous les fichiers d'un certain type dans un répertoire (path => /home/log/*.lst) - Le paramètre start_position permet d'indiquer ou la lecture du fichier commence.
- Le paramètre sincedb_path permet de préciser l'emplacement où sera créé/chargé le fichier
.sincedb_*qui récupère les noms et la position de la dernière ligne des fichiers traités afin de ne pas les réécrire et de recommencer à la suite en cas d'interruption. Si le paramètre n'est pas présent le fichier se trouvera dans le répertoire home de l'user. Dans le cadre de test j'ai sélectionné l'emplacement «/dev/null» mais je conseille de laisser l'option par défaut et de supprimer le fichier.sincedbgénérer en cas d'erreur pour une réécriture complète sans oublier de supprimer au préalable l'index généré. - Le paramètre codec permet de choisir comme son nom d'indique le codec, UTF-8, ISO-8859,… pour le traitement des fichiers.
Filter
Plugin Grok
Le plugin Grok permet de parser chaque ligne d'un fichier à l'aide de pattern, pré-défini ou à définir.
filter {
grok {
patterns_dir => "/etc/logstash/conf.d/patterns"
match => {
"message" => "%{USER:accesp}%{SPACE}%{INT:nfile}%{SPACE} [...]"
}
remove_field => ["nfile", "accesp", "message"]
}
[...]
}
- Le paramètre patterns_dir permet d'indiquer le répertoire où se trouvent les patterns personnalisés. En effet étant donné que le fichier en entré n'est pas un fichier de log, nous avons dû créer plusieurs patterns personnalisés. Pour information il est aussi possible de créer un pattern personnalisé directement dans le plugin.
- Le paramètre match est sans doute le plus important, il récupère ligne par ligne et parse selon le format sélectionné. Le champ ‘message' correspond à un événement du fichier (soit une ligne complète) et vient ensuite la chaîne de regex pré-défini dans le pattern.
- Le paramètre remove_field est utilisable dans la quasi intégralité des plugins filters. Il permet de supprimer un ou plusieurs champs. Dans notre cas nous supprimons le champ ‘message' que l'on vient de parser ainsi que les champs dont nous n'avons pas besoin :
remove_field => ["nfile","accesp","message"]
Le format du paramètre match est comme suit %{PATTERN:champ:option}
PATTERN: Regex correspondant au type de champchamp: Nom souhaité pour le champoption: Par défaut grok convertit tous les champs en string, l'option permet d'indiquer un autre type (int ou float)
Par exemple pour un fichier comprenant le format suivant:
31/11/2012 55.3.244.1 GET /index.html 15824 0.043
01/12/2012 55.3.246.5 GET /mnt/prog.txt 15754 0.058
Le paramètre aura la forme suivante:
match => {"message" => "%{DATE:date}%{SPACE}%{IP:client}%{SPACE}%{WORD:method}%{SPACE}%{PATH:request}%{SPACE}%{NUMBER:bytes:int}%{SPACE}%{NUMBER:duration:float}"}
Cela donnera en sortie:
date : 31/11/2012 date : 01/12/2012
client: 55.3.244.1 client: 55.3.246.5
method: GET method: GET
request: /index.html request: /mnt/prog.txt
bytes: 15824 bytes: 15754
duration: 0.043 duration: 0.058
Plugin Mutate
Ce plugin permet d'effectuer des mutations générales sur les champs. Vous pouvez renommer, supprimer, remplacer et modifier des champs.
filter {
if[year] =~ /^[01][0-9]|2[0-3]:[0-5][0-9]$/ {
mutate { replace => {"year" => "%{+YYYY}"} }
}
mutate {
add_field => {"filegroup" => "not_classed"}
replace => {"date" => "%{date} %{year}"}
}
[...]
}
Dans notre cas, nous l'avons utilisé pour modifier une date puis l'assembler, petite explication :
Voici le format des dates en UNIX et LINUX:
Les formats de dates sont différents selon que la date est de cette même année ou d'une année antérieure. Cela ne facilite donc pas l'intégration à Elasticsearch. Nous avons donc séparé au niveau du plugin Grok, la date en 2 champs.
La première nommée date comprenant le mois et le jour du mois:
Pattern : (%{MONTH}%{SPACE}%{DAYNUM})
La seconde nommée year comprenant l'heure ou la date :
Pattern : (%{HOUR}:%{MINUTE}|%{YEAR})
Nous pouvons ensuite mettre une condition disant que si le champ year est une heure, nous la remplacerons par l'année en cours, soit:
Il ne reste plus maintenant qu'à ajouter au champ date le champ year:
Plugin Date
Ce plugin permet d'analyser la date et ou l'heure d'un champ et de la transformer en timestamp.
filter {
date {
match => ["date", "MMM dd YYYY", "MMM d YYYY"]
remove_field => ["date", "year"]
}
[...]
}
Avec le paramètre match nous indiquons où se trouve le champ date puis son format. Dans notre cas le champ date transformé précédemment peut encore avoir 2 formes:
Le paramètre match aura donc le format suivant:
Nous constatons que le plugin reconnaît automatiquement les mois sous forme de lettre (Seulement en Anglais).
Après cela le plugin va interpréter la date du champ et la copier dans le champ @timestamp. Pour information, par défaut le champ @timestamp contient la date et l'heure de l'ajout de l'event.
Avec le paramètre remove_field nous supprimons les champs date et year étant donné que le champ @timestamp contient maintenant notre date. Nous allons donc les supprimer:
Plugin Ruby
Ce plugin permet entre autre d'insérer du code Ruby, ce qui est très pratique pour faire des opérations plus complexe sur un champ.
filter {
ruby {
code => "
f = File.basename(event['path'], '.lst').downcase
event['[@metadata][srv]'] = f.split('-').first
event['[@metadata][xtime]'] = f.split('-').last
event['file_path'] = File.dirname(event['mypath']).downcase
event['file_name'] = File.basename(event['mypath'], '.*').downcase
event['file_ext'] = File.extname(event['mypath']).downcase
event['file_fmt_ext'] = event['file_ext'].split(/[-_:]/).first
"
remove_field => ["mypath", "host", "path", "@version"]
}
[...]
}
Le paramètre code permet d'exécuter le code. Dans notre cas, nous avons utilisé du code Ruby pour extraire le nom du serveur présent dans le nom du fichier en entrée, ou encore pour extraire un fichier et son extension depuis un champ path récupéré précédemment avec le plugin Grok:
code => "
event['file_path'] = File.dirname(event['mypath']).downcase
event['file_name'] = File.basename(event['mypath'], '.*').downcase
event['file_ext'] = File.extname(event['mypath']).downcase
"
event[] correspond à un champ. Dans le cas si dessous nous allons donc créer 3 nouveaux champs file_path, filename et file_ext. Et chaque champ fait appel au champ mypath récupéré précédemment avec le plugin Grok. Les fonctions File.dirname(), File.basename() et File.extname() récupèrent respectivement le répertoire, le nom et l'extension du fichier. La fonction downcase met en minuscule le champ (pour la lisibilité).
Pour exemple, si event['mypath'] = /apps/PROG/file.txt
Les 2 champs [@metadata][srv] et [@metadata][xtime] sont des champs de métadonnées qui ne sont pas sérialisés. Cela signifie que les champs ajoutés ne seront pas inclut en sortie. Autrement dit, ils n'apparaîtrons pas dans Elasticsearch mais pourrons être utilisés dans notre code. Ces 2 champs seront utilisés pour nommer l'index.
Le champ file_fmt_ext contient l'extension du fichier découpé après un séparateur et cela pour plus de clarté:
Cela donnera pour exemple:
Nous pouvons aussi utiliser toutes les autres fonctions Ruby selon ce que l'on souhaite faire; Voir documentation Ruby: https://www.ruby-lang.org/fr/documentation
Le paramètre remove_field, vu précédemment nous sers là à supprimer les champs qui ne nous sont plus utiles comme par exemple mypath une fois que nous avons extrait les informations nécessaires (file_path, file_name et file_ext).
Nous pouvons aussi supprimer les champs par défaut qui ne nous serons pas forcément nécessaire dans notre cas, à savoir:
@version: version du documentpath: nom et chemin du fichier en entréehost: nom de la machine
Output
Plugin Elasticsearch
Ce plugin contient les informations du cluster elasticsearch sur lequel envoyer les données fraîchements parsées.
output {
elasticsearch {
host => "localhost"
index => "filelist-%{[@metadata][xtime]}-%{[@metadata][srv]}"
cluster => "elastic-cluster"
node_name => "filelist-node"
document_type => "%{[@metadata][srv]}"
}
}
- Le paramètre host contient l'adresse du cluster elasticsearch.
- Le paramètre index contient le nom de l'index d'elasticsearch. Dans mon cas j'ai récupéré le nom et le type d'horodatage (atime, ctime ou mtime) du serveur découpé dans le nom du fichier en entrée (Voir plugin Ruby 4.3.4).
- Le paramètre cluster contient le nom du cluster elasticsearch.
- Le paramètre node_name contient le nom du noeud qui sera définit dans elasticsearch pour l'ajout des données. Par défaut le nom est généré en interne pas Elasticsearch.
- Le paramètre document_type contient le nom du type de document elasticsearch (champ «
_type»)